索引详解(B-tree、bitmap)
索引概述
索引是建立在表的一列或多列上的辅助数据库对象。可以将索引比喻成一本书的目录:通过目录,我们能快速找到所需的内容。数据库索引的主要功能是提高查询速度以及辅助完整性检查。
书的目录将书名与页码对应,同样的,数据库索引通常将列值连同 ROWID 存储在一起。ROWID 包含了存储列值的表在磁盘中的物理位置(涉及磁盘存储机制,此处不再赘述)。通过 ROWID,Oracle 等数据库可以以最小的代价快速检索到相应内容。如果没有索引,数据库就必须进行全表扫描来查看是否包含数据。
但是,创建索引也有一定代价:
- 维护成本:列值修改的同时也要修改索引,以确保索引与列值保持一致。
- 资源消耗:索引会消耗磁盘空间以及系统资源。
因此,创建索引时需要保障其合理性。
B 树索引
通常创建的索引一般都是 B-Tree(B 树)索引,一般分为聚集索引(Clustered Index)和非聚集索引(Non-Clustered Index)。
网上有一张结构图很形象地表示了 B 树的原理,参考如下:
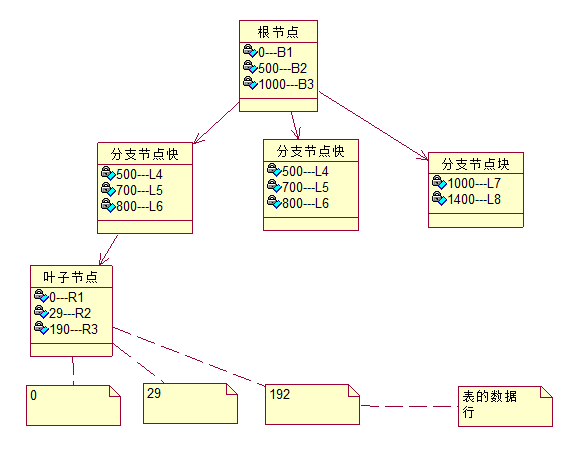
索引由键值和逻辑指针构成。根节点中的 0、500、1000 指的是所链接的键值的最小值,B1、B2、B3 指分支节点块的地址。
聚集索引和非聚集索引的区别在于表记录的排列顺序是否和索引的排列顺序一致:
- 聚集索引:叶子节点就是数据节点。
- 非聚集索引:叶子节点为每一真正数据行存储的“键值对”,并且还包含一个指针偏移量。根据页指针及指针偏移量,就能定位到具体的数据行。
通过以上原理可知,聚集索引查询速度较快,但因为要保证表记录的排列顺序与索引一致,在修改表记录的同时也要更新索引数据,因此修改速度较慢。把记录插入到相应的位置必须在索引的数据页中全部重排,也降低了执行速度。非聚集索引指定了索引中的逻辑顺序,但记录的物理顺序和索引顺序不一致。
- Oracle 默认是非聚集索引。
- SQL Server 则默认为每一个主键创建聚集索引。
由于表的物理顺序只有一种,因此每张表也只能有一种聚集索引。
位图索引
Bitmap 索引即位图索引,适用于候选值较少却又广泛出现、但不频繁更新的列,比如性别、婚否等。
以下有一张示例表:
| 编号 | 婚否 | 性别 |
|---|---|---|
| 张三 | 未 | 女 |
| 李四 | 已 | 男 |
| 钱五 | 未 | 男 |
转为位图则是:
性别位图:
| 女 | 男 |
|---|---|
| 1 | 0 |
| 0 | 1 |
| 0 | 1 |
婚否位图:
| 已婚 | 未婚 |
|---|---|
| 0 | 1 |
| 1 | 0 |
| 0 | 1 |
即性别为男的向量为 011,性别为女的向量为 100;已婚向量为 010,未婚向量为 101。则通过向量之间的位运算(异或:相同为 0,不同为 1)获得结果集为:
| 性别 | 已婚组合 | 未婚组合 |
|---|---|---|
| 女 | 111 | 110 |
| 男 | 101 | 001 |
执行 SQL 语句:
SELECT * FROM t WHERE 性别 LIKE '女' AND 婚否 LIKE '未';获得的向量对应结果集就是结果。位图索引的操作实际上是通过位运算获得最符合的叶子节点,然后不断向上扫描得到的;而 B 树索引则是通过从根节点开始不断往下扫描得到。
复合索引
创建索引:
CREATE INDEX idx_name ON t (name, id, sex);执行查询操作:
SELECT * FROM t WHERE name = 'zhang' AND sex LIKE 'male';这时查询不再扫描全表,而是直接从索引中拿数据。这就是覆盖索引。通常根据 WHERE 后的条件建立复合索引。
有一点要注意(最左前缀原则):
SELECT * FROM t WHERE name = 'zhang';
SELECT * FROM t WHERE sex LIKE 'male';执行这两个 SQL 语句时,虽然 WHERE 后的条件列值建立了复合索引,但只对起始列有效,非起始列则无用。
索引的使用限制
- 使用不等于(
<>)操作符:数据库可能仍然执行全表扫描。可用OR替代。 - 使用
NULL、NOT NULL关键字:因为数据库对NULL的处理机制特殊,建索引时建议将索引的列设为非空值。 使用函数:如果没有基于函数本身的索引,则索引无法执行。但是将函数应用在索引上则可以执行。比如:
SELECT * FROM t WHERE date = TO_DATE('1998-3-27', 'yyyy-mm-dd');- 比较类型不匹配:比如一个
VARCHAR2类型和INTEGER类型进行比较。 - 使用
LIKE '%X%'进行模糊查询:前缀模糊查询通常无法利用索引。
参考链接
- http://www.cnblogs.com/kissknife/archive/2009/03/30/1425534.html
- http://blog.itpub.net/17203031/viewspace-695055/
说明:本文部分技术细节(如 Oracle/SQL Server 默认索引行为、NULL 值索引处理等)可能因数据库版本不同而有所差异,请以实际使用的数据库版本文档为准。参考链接为早期技术博客,内容供原理参考。
版权声明:本文为原创文章,版权归 戴老师的博客 所有,转载请联系博主获得授权。
本文地址:https://1diff.fun/archives/suo-yin-xiang-jie-b-treebitmap.html
如果对本文有什么问题或疑问都可以在评论区留言,我看到后会尽量解答。
