算法基础-前缀和
前缀和
一、什么是前缀和?
一维前缀和(1D Prefix Sum)
给定一个一维数组 ![[公式]](https://www.zhihu.com/equation?tex=x) 和该数组的一维前缀和数组 ![[公式]](https://www.zhihu.com/equation?tex=y) ,则 ![[公式]](https://www.zhihu.com/equation?tex=x) 和 ![[公式]](https://www.zhihu.com/equation?tex=y) 满足以下关系:
二维前缀和(2D Prefix Sum)
给定一个二维数组 ![[公式]](https://www.zhihu.com/equation?tex=a) 和该数组的二维前缀和数组 ![[公式]](https://www.zhihu.com/equation?tex=b) (其同样是个二维数组),则 ![[公式]](https://www.zhihu.com/equation?tex=a) 和 ![[公式]](https://www.zhihu.com/equation?tex=b) 满足以下关系:
公式可能较为抽象,结合下图会更易于理解:
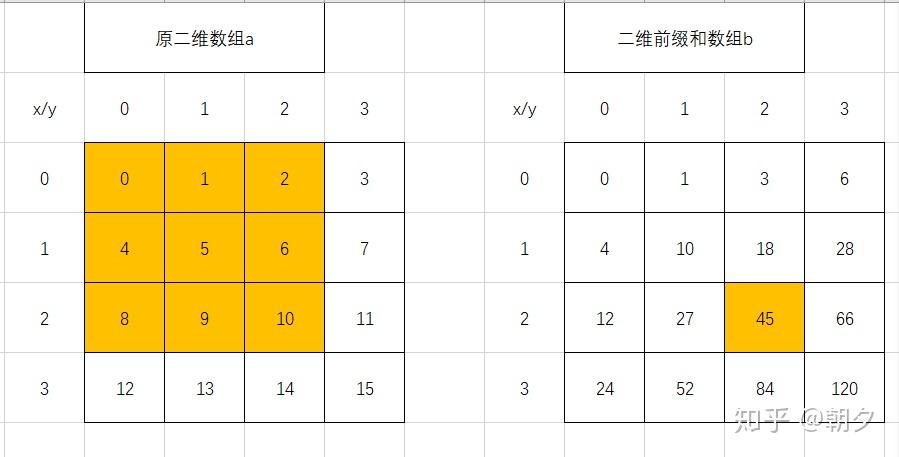
图中右侧标注橙色的二维前缀和元素,其值等于左侧原二维数组中对应橙色区域所有元素的总和。
二、如何得到前缀和?
一维前缀和
通过观察可以发现递推关系:![[公式]](https://www.zhihu.com/equation?tex=y_n%3Dy_%7Bn-1%7D%2Bx_n) 。
代码实现如下:
for(int i = 0; i < n; i++) {
if(i == 0)
y[i] = x[i];
else
y[i] = y[i-1] + x[i];
}二维前缀和
二维前缀和本质上是计算矩阵内值的累加和。一个矩阵的和可以由两个行数或列数少一的子矩阵组合后,删去重合部分,再加上右下角当前元素的值来构成。递推公式如下:
代码实现如下(注意行列索引与公式的对应关系):
for(int y = 0; y < n; y++) // n 行
for(int x = 0; x < m; x++) // m 列
{
if(x == 0 && y == 0)
b[y][x] = a[y][x]; // 左上角的值
else if(x == 0)
b[y][x] = b[y-1][x] + a[y][x]; // 第一列
else if(y == 0)
b[y][x] = b[y][x-1] + a[y][x]; // 第一行
else
b[y][x] = b[y-1][x] + b[y][x-1] - b[y-1][x-1] + a[y][x];
}三、前缀和有什么用?
3.1 说明
前缀和是一种典型的预处理技术,用于降低查询时的时间复杂度。
场景举例: 给定 ![[公式]](https://www.zhihu.com/equation?tex=n) 个整数,然后进行 ![[公式]](https://www.zhihu.com/equation?tex=m) 次询问,每次询问求一个区间内值的和。
- 暴力解法: 每次询问都需要从区间左端点循环到区间右端点求和,时间复杂度较高。
- 前缀和优化: 预先求出该数组的一维前缀和。则区间和 ![[公式]](https://www.zhihu.com/equation?tex=ans%3Dy%5BR%5D-y%5BL-1%5D) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=L) 和 ![[公式]](https://www.zhihu.com/equation?tex=R) 是给定的区间边界。每次询问可直接输出答案,整体时间复杂度降为 ![[公式]](https://www.zhihu.com/equation?tex=O%28N%2BM%29) 。
3.2 一些前缀和例题
3.2.1 成绩百分比(改编自网易笔试题)
班级中共有 ![[公式]](https://www.zhihu.com/equation?tex=n) 位同学,其编号为 1~ ![[公式]](https://www.zhihu.com/equation?tex=n) 。考试中每位同学都取得了一定的成绩。
接下来进行 ![[公式]](https://www.zhihu.com/equation?tex=m) 次询问,每次询问给出一位同学的编号,求这位同学的成绩在班级中的百分比。
百分比求法:不超过这位同学成绩的班级人数(包括这位同学)/ 总人数×100%。
( ![[公式]](https://www.zhihu.com/equation?tex=2%3C%3Dm%2Cn%3C%3D100000) ,成绩 ![[公式]](https://www.zhihu.com/equation?tex=a_i%3C%3D150) )。
解法① 暴力解法
每次询问都遍历所有同学,时间复杂度 ![[公式]](https://www.zhihu.com/equation?tex=O%28N%C3%97M%29) 。由于数据规模较大,该方法极易超时。
解法② 排序 + 二分查询
开一个新的数组,将班级内所有同学的成绩进行排序。每次查询时,先将这位同学的成绩取出,然后通过二分法在已排序的数组中寻找位次并输出。
时间复杂度 ![[公式]](https://www.zhihu.com/equation?tex=O%28NlogN%2BMlogN%29) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=NlogN) 是排序的复杂度,![[公式]](https://www.zhihu.com/equation?tex=MlogN) 是 ![[公式]](https://www.zhihu.com/equation?tex=m) 次查询的复杂度。该方法可行,但并非最优解。
解法③ 前缀和
根据题意可以发现,由于成绩分数都小于等于 150,数据范围较小,可以考虑使用桶排序思想。
- 先通过桶排序得到考到每个分数的人数。
- 接下来通过前缀和来计算不超过该分数的人数,式子如下:
![[公式]](https://www.zhihu.com/equation?tex=nohigher%5Bi%5D%3Dnohigher%5Bi-1%5D%2Bpeople%5Bi%5D)
其中 ![[公式]](https://www.zhihu.com/equation?tex=i) 表示分数,![[公式]](https://www.zhihu.com/equation?tex=people%5Bi%5D) 表示考到该分数的人数。
这样查询时的时间复杂度就变成了 ![[公式]](https://www.zhihu.com/equation?tex=O%281%29) 。
3.2.2 数列找不同(洛谷 P3901)
这题准确来说是维护前缀最大值,但核心思想与前缀和一致。
只需要 ![[公式]](https://www.zhihu.com/equation?tex=O%28n%29) 的预处理,就能达成 ![[公式]](https://www.zhihu.com/equation?tex=O%281%29) 的查询效率。若不采用此方法,则可能需要使用莫队算法等更复杂的方案。
3.2.3 在你窗外闪耀的星星(洛谷 P3353)
这道题的题目描述较为独特。
解题时无需使用线段树,配合前缀和即可高效完成。
版权声明:本文为原创文章,版权归 戴老师的博客 所有,转载请联系博主获得授权。
本文地址:https://1diff.fun/archives/suan-fa-ji-chu-qian-zhui-he.html
如果对本文有什么问题或疑问都可以在评论区留言,我看到后会尽量解答。
