简述一个大型交易网站的发展旅程
编者注:本文为历史博文归档,记录了一个典型交易网站架构的演进历程。文中涉及的 JDK、框架与工具链版本请以当前官方文档为准。部分引用外链图片可能因年代久远失效,阅读时请注意时效性。
功能定义
在架构演进之前,首先明确系统的核心功能模块:
- 商品模块:商品展示、商品管理等。
- 交易模块:创建交易、交易管理等。
- 用户模块:用户注册、信息查询、用户管理等。
技术演进
第一版:简单基础版
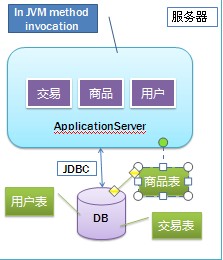
出于快速迭代与开发的考量,第一版往往采用单台机器构建(此处以 Java 技术栈为例)。这种方案开发方便且快速,采用的技术甚至可以是基础的 JSP、Servlet 等。
技术特点:
- 包含三个核心功能模块。
- 数据库中仅对应三个表。
- 连接数据库使用 JDBC。
- 模块之间的调用是 JVM 内部的方法调用。
第二版:应用与数据库分离
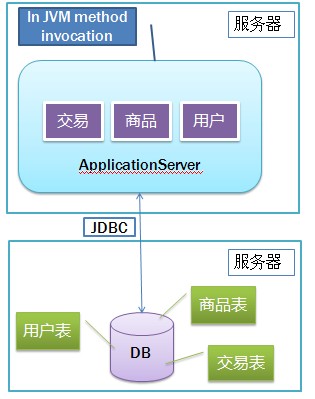
随着访问量的上升,单台机器的负载越来越高,这是网站遇到的第一个性能瓶颈。此时一般的解决方案很简单:将应用服务器(App)和数据库服务器(DB)拆分到两台机器上。
这种改造实现了应用服务器和数据服务器的分离,对开发、测试及部署流程几乎没有影响。
第三版:多台应用服务器
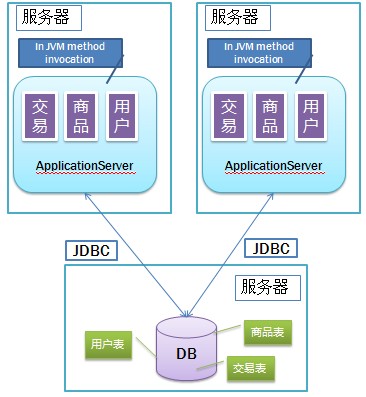
访问量持续上升,应用服务器的压力变得很大,第二版的简单设计已经无法支撑。因此,不得不继续对其进行改造,将应用从 1 台拆分到两台甚至多台。
此时会遇到的核心问题是 Session 一致性。Session 数据通常保存在服务器内存中,服务器拆分前后,如何维护 Session 的一致性?例如,当用户先访问 A 服务器,随后页面跳转到了 B 服务器,此时 A 中有该用户的 Session,而 B 没有,会造成访问错误。
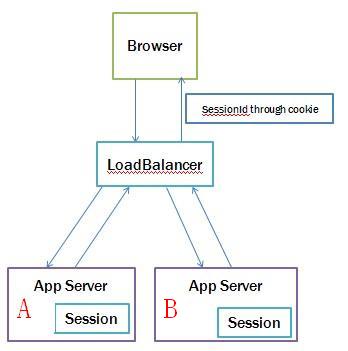
解决方案:
- Session-Sticky
用户访问一次后,同一个 Session 周期内,所有的请求都定向到这台服务器。只有当浏览器关闭或者服务器挂掉,Session 才会丢失。 Session Replication
策略是复制会话,即一个用户访问一次就把 Session 复制到所有的服务器或这一部分服务器。- 优点:如果正访问的服务器 Down 机,用户可以自动被转到别的服务器,Session 不丢失。
- 缺点:效率较低,网络开销大。
- 基于 Cookie
将 Session 数据加密后存储在客户端 Cookie 中。 - Session 数据集中独立存储
使用独立的缓存服务器(如 Redis、Memcached)集中存储 Session 数据。
注意:
- Web 中的 Session 指用户在浏览某个网站时,从进入网站到浏览器关闭所经过的这段时间。A 用户和 C 服务器建立连接时所处的 Session,同 B 用户和 C 服务器中建立连接时所处的 Session 是两个不同的 Session。
- 当用户在相同机器的应用程序的 Web 页之间跳转时,存储在 Session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。
第四版:数据库读写分离
随着业务的发展,数据库会成为瓶颈。通常读写比例很高(读数据库的人很多,而写数据库的人相对而言少)。
解决方案:通过读写分离,降低主库的压力。

第五版:引入搜索、缓存与 CDN
搜索、缓存与分布式存储
为了方便用户更快地找到商品,系统引入搜索引擎;为了减轻数据库的访问压力和提高访问速度,引入了缓存;为了解决海量数据存储,引入了分布式文件存储。
引入 CDN 系统
CDN 的全称是 Content Delivery Network,即内容分发网络。其目的是通过在现有的 Internet 中增加一层新的网络架构,将网站的内容发布到最接近用户的网络“边缘”,使用户可以就近取得所需的内容,解决 Internet 网络拥挤的状况,提高用户访问网站的响应速度。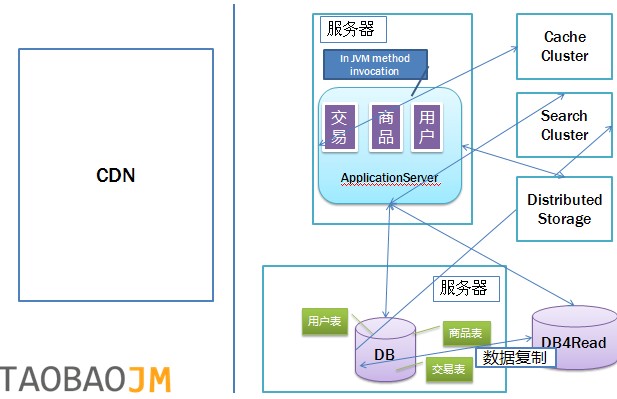
第六版:数据库垂直拆分
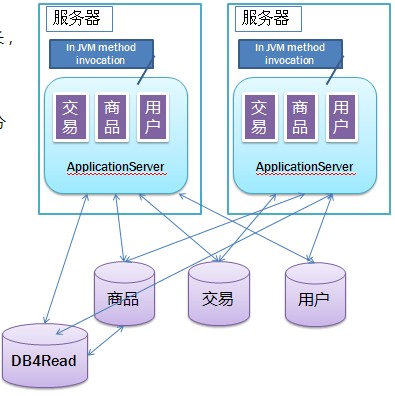
虽然实现了读写分离,但随着业务的增长,主库还是会遇到瓶颈。这时,我们可以根据功能对数据库进行切分。具体如下图,原先的数据库中包含了所有数据,现在将其进行“垂直切分”——即不同的数据库存储不同类型的表。
在这个交易系统中,就是分库为商品表、交易表、用户表。
这时需要注意的问题包括:
- 事务影响:对之前的一些有事务的 SQL 可能造成影响。
- Join 操作影响:对之前的多表 Join 的 SQL 可能造成影响。原先多张表是在同一数据库中,用 Join 操作是相当容易的;现在不同的表在不同的数据库中,一个 Join 操作要用到不同的表,此时就需要访问不同的服务器。
参考资料:事务讲解 http://blog.csdn.net/lengyuhong/archive/2010/11/02/5981872.aspx
第七版:数据库水平拆分
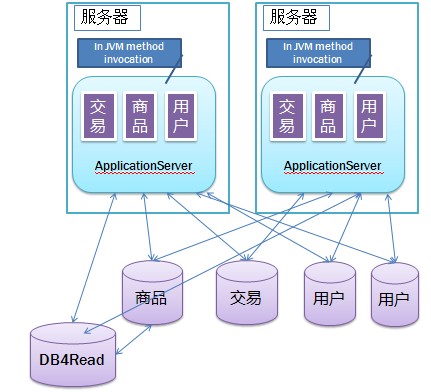
用垂直拆分后,能够缓解很大的问题,但如果数据库和数据量的原因,造成单台数据库还是不能够负担,这时就需要对数据库进行水平拆分。具体如下图中的用户表。
水平切分和垂直切分的不同在于扩展方式上:
- 垂直切分:原先一台服务器一个数据库三张表 TA、TB、TC。垂直切分就是三台服务器,每台服务器一个数据库,服务器 A 中存 TA 表,服务器 B 存 TB 表,服务器 C 存 TC 表。
- 水平切分:也是三台服务器,每台服务器一个数据库,服务器 A、B、C 中都存有 TA、TB、TC 三张表(通常指按行拆分,此处原文描述似有混淆,按常规理解水平拆分应为同一表结构分布在不同库,此处保留原文逻辑但需注意实际架构中水平拆分通常指分片)。
这样拆分后,还是带来了新的问题:
- 路由
比如有两台服务器,都存有用户数据。当我们要插入一条用户信息时,应该插入到哪台服务器的数据库上?当我们要检索一条用户信息时,我们应该到哪台服务器上查找? - 分页
- 合并
个人觉得 2、3 两种情况通常会一起发生。比如我们要查出前一百名的用户(具体比如在网站购物最多的用户),此时可能的情况是这前 100 名中 60 个在数据库 A,40 个在数据库 B。 - 唯一主键
用户表分布在两台数据库中,如何做到两台数据库中的用户表有唯一主键。
第八版:服务化架构
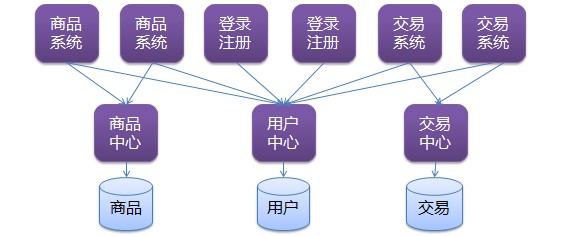
引入服务化(SOA/微服务雏形),它可以解决两个问题:
- 解决了业务核心的稳定和一致的问题。
- 解决了重要数据库的连接数的问题。
第九版:引入消息中间件
- 解耦:降低系统模块间的耦合度。
- 异步:提高系统响应速度与吞吐量。
技术总结
最后系统的架构:

大致总结这个网站的技术发展过程:
- 1 台机器 + 1 个应用 + 1 个 DB
- 应用和 DB 分到两个机器
- 应用部署多机器,走入集群
- DB 读写分离
- 引入搜索
- 引入 Cache
- 引入分布式存储
- 引入 CDN
- 数据库垂直拆分
- 数据库水平拆分
- 应用的拆分
- 服务化
- 引入消息中间件
说明
技术时效性说明:本文描述的架构演进路径属于经典的互联网高并发解决方案,主要基于 2010 年前后的技术背景(如 JSP/Servlet、早期 SOA 等)。当前实际开发中,容器化(Docker/K8s)、云原生数据库、Serverless 及更成熟的微服务框架已成为主流,请结合当前技术栈参考借鉴。
版权声明:本文为原创文章,版权归 戴老师的博客 所有,转载请联系博主获得授权。
本文地址:https://1diff.fun/archives/jian-shu-yi-ge-da-xing-jiao-yi-wang-zhan-de-fa-zhan-lv-cheng.html
如果对本文有什么问题或疑问都可以在评论区留言,我看到后会尽量解答。
