基于布尔表达式的广告索引设计
问题背景
广告主在广告投放平台勾选定向条件后,当用户发起请求时,广告引擎需要快速筛选出符合定向条件的广告。通常容易想到如下代码结构:
Attributes = list<Attribute> // 用户的流量标签,例如:用户的年龄、性别...
for (Ad ad : ads) {
check attributes for each ad. // 对于每一个广告检查是不是符合流量标签,挑选广告
}然而,该方案的时间复杂度随广告数量线性增长,显然无法满足业务发展需要。无论是在品牌广告还是竞价广告场景中,该问题普遍存在。自然地,我们想到建立索引,那么索引结构如何设计就成为问题的关键。
索引结构
两层索引结构
为了说明两层索引结构,我们定义如下术语:
- Attribute(属性):单个流量标签,包含两个信息:属性类别和属性取值。例如:
AGE: 5。 - Assignment(赋值):多个流量标签组成的用户画像。例如:
AGE: 5, GENDER: 1, NETWORK: 1。 - Conjunction(合取范式):布尔表达式的合取范式。例如:
AGE ∈ (4,5,6) ∧ GENDER ∈ (1)。 - Predicate(谓词):布尔表达式的一个子表达式。例如:
AGE ∈ (4,5,6),GENDER ∈ (1)。
两层索引设计的主要思想是:从 Assignment 找出包含这些流量标签的 Conjunction,筛选满足条件的 Conjunction,再根据筛选出的 Conjunction 找出满足条件的广告集合。下面我们举个例子:
假设线上有 7 个广告,它们的定向条件如下。其中 Ad3 和 Ad7 定向条件相同;Ad6 包含反向定向,即该广告不能出在 AppInterest 标签为 19-1 的用户上面。
Ad1 定向:PlacementType ∈ (2)
Ad2 定向:PlacementType ∈ (2) ∧ AppInterest ∈ (15-0, 19-1) ∧ InstalledApp ∈ (30202)
Ad3 定向:PlacementType ∈ (2) ∧ AppInterest ∈ (15-0, 19-1) ∧ NetworkType ∈ (1)
Ad4 定向:PlacementType ∈ (2) ∧ AppInterest ∈ (19-1)
Ad5 定向:PlacementType ∈ (2) ∧ InstalledApp ∈ (30202) ∧ NetworkType ∈ (1)
Ad6 定向:PlacementType ∈ (2) ∧ IpGeo ∈ (141) ∧ NetworkType ∈ (1) ∧ AppInterest ∉ (19-1)
Ad7 定向:PlacementType ∈ (2) ∧ AppInterest ∈ (15-0, 19-1) ∧ NetworkType ∈ (1)对应定向条件可归纳为 6 个 Conjunction,编号如下:
| conjunctionId | conjunction | size |
|---|---|---|
| 1 | PlacementType ∈ (2) | 1 |
| 2 | PlacementType ∈ (2) ∧ AppInterest ∈ (19-1) | 2 |
| 3 | PlacementType ∈ (2) ∧ IpGeo ∈ (141) ∧ NetworkType ∈ (1) ∧ AppInterest ∉ (19-1) | 3 |
| 4 | PlacementType ∈ (2) ∧ InstalledApp ∈ (30202) ∧ NetworkType ∈ (1) | 3 |
| 5 | PlacementType ∈ (2) ∧ AppInterest ∈ (15-0, 19-1) ∧ InstalledApp ∈ (30202) | 3 |
| 6 | PlacementType ∈ (2) ∧ AppInterest ∈ (15-0, 19-1) ∧ NetworkType ∈ (1) | 3 |
其中,conjunctionId 为编号,conjunction 为布尔表达式内容,size 为 ∈ 语句的个数。
可以建立 conjunctionId 到 Ad 的索引如下:
conjunction1 -> Ad1
conjunction2 -> Ad4
conjunction3 -> Ad6
conjunction4 -> Ad5
conjunction5 -> Ad2
conjunction6 -> Ad3, Ad7流量标签到布尔表达式的索引如下:
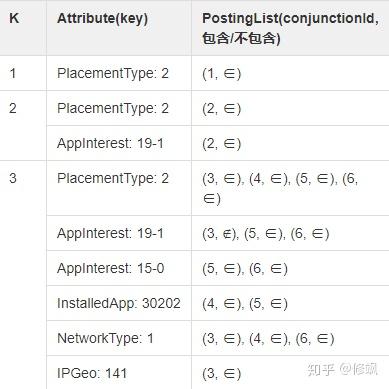
流量标签到布尔表达式索引
如上图,建立 K-Index:
- K:代表 Conjunction 的 size 大小。
- PostingList:代表包含或不包含这个 Attribute 的 Conjunction 列表。
算法原理
我们沿用上面的例子说明,最后给出核心算法的伪代码。假设现在来了一个用户画像 Assignment:
PlacementType: 2
AppInterest: 19-1
NetworkType: 1由于有三个流量标签,那么满足条件的只可能是 1-Index、2-Index 或 3-Index。这就是为什么建索引时需要建立 K-Index,加上 K-Index 可以根据数目进行算法剪枝。同时,每一个 PostingList 中的 Conjunction 都已按照 ConjunctionId 升序排列。
我们以检测 3-Index 为例。根据 Assignment 可以从索引里面取到如下 Conjunctions:
PlacementType: 2 (3, ∈), (4, ∈), (5, ∈), (6, ∈)
AppInterest: 19-1 (3, ∉), (5, ∈), (6, ∈)
NetworkType: 1 (3, ∈), (4, ∈), (6, ∈)核心逻辑:需要判断当前最小的 ConjunctionId 至少出现在 3 个 PostingList 中,且不能出现 ∉ 的关系。
每次 check 完成之后按照 ConjunctionId 重排序(方便检测是不是至少出现在 3 个 PostingList 中)。过程如下:
PlacementType: 2 (3, ∈), (4, ∈), (5, ∈), (6, ∈)
AppInterest: 19-1 (3, ∉), (5, ∈), (6, ∈)
NetworkType: 1 (3, ∈), (4, ∈), (6, ∈)
-------------------------------------------------------
MatchedConjunction = [] (check Conjunction3,发现出现了∉,故不满足)
PlacementType: 2 (4, ∈), (5, ∈), (6, ∈)
NetworkType: 1 (4, ∈), (6, ∈)
AppInterest: 19-1 (5, ∈), (6, ∈)
-------------------------------------------------------
MatchedConjunction = [] (check Conjunction4,发现只出现在两个中,故不满足)
PlacementType: 2 (5, ∈), (6, ∈)
AppInterest: 19-1 (5, ∈), (6, ∈)
NetworkType: 1 (6, ∈)
-------------------------------------------------------
MatchedConjunction = [] (check Conjunction5,发现只出现在两个中,故不满足)
PlacementType: 2 (6, ∈)
AppInterest: 19-1 (6, ∈)
NetworkType: 1 (6, ∈)
-------------------------------------------------------
MatchedConjunction = [6] (check Conjunction6,至少出现在三个中,且没有∉关系,满足)按照该算法继续检测 2-Index、1-Index。得到最终结果:MatchedConjunction = [1, 2, 6]。再根据 MatchedConjunction 检索出广告 MatchedAds = [Ad1, Ad4, Ad3, Ad7]。
算法伪代码
C++ 版本可以参考《计算广告》P225。
维度爆炸问题
有的读者可能会觉得这里会出现维度爆炸的问题,比如有 50 个兴趣标签,5 个年龄段标签,2 个性别标签。最极端的情况可能会出现:
50 * 5 * 2 * ... = 100 * ...随着定向维度的增加而爆炸。实际上并不会,因为定向维度是取决于广告的规模的。最极端情况,假设我们线上有 100w 的广告,且这 100w 的广告定向标签都不一样,那么问题规模也是 100w,并不会出现维度爆炸。另外,实际上线上大量广告的定向标签是重复的,100w 的广告定向的 Conjunction 数量,远远小于广告数量。
用 ES 可以做吗?
这篇文章发出去之后,虽然点赞数寥寥无几,但是私信我的人蛮多。在这里提供另一种思路:如果你的公司是一个小公司,也没必要因为性能自己造轮子,直接使用 Elasticsearch (ES) 进行索引即可。ES 检索的 DSL 条件的伪代码如下:
[(不存在性别定向)|| (存在性别定向且满足条件)]
&& [(不存在年龄定向)|| (存在年龄定向且满足条件)]
&& [(不存在标签定向)|| (存在标签定向且满足条件)]
...这样就可以把通投的(无任何定向)广告和有定向且满足条件的广告检索出来。
例如:请求是 26 岁的男性用户,那么实际的 ES DSL 为:
{
"must": [
{
"bool": {
"should": [
{
"bool": {
"must_not": {
"exists": {
"field": "age"
}
}
}
},
{
"bool": {
"should": [
{
"range": {
"age.min": {
"from": null,
"to": 26,
"include_lower": true,
"include_upper": true
}
}
},
{
"range": {
"age.max": {
"from": 26,
"to": null,
"include_lower": true,
"include_upper": true
}
}
}
]
}
}
]
}
},
{
"bool": {
"should": [
{
"bool": {
"must_not": {
"exists": {
"field": "gender"
}
}
}
},
{
"term": {
"gender": "男"
}
}
]
}
}
]
}参考资料
- http://theory.stanford.edu/~sergei/papers/vldb09-indexing.pdf
- https://pdfs.semanticscholar.org/28d5/eae010074ea82a635e9c36d5a420dba949fa.pdf
- https://book.douban.com/subject/26596778/
说明
- 文中 Elasticsearch DSL 示例使用了
include_lower和include_upper参数,该参数在 ES 2.0 版本后已废弃,新版本建议使用gte/lte语法。 - 本文所述索引设计思路主要基于传统广告引擎场景,具体实现需结合业务数据规模与延迟要求评估。
版权声明:本文为原创文章,版权归 戴老师的博客 所有,转载请联系博主获得授权。
本文地址:https://1diff.fun/archives/ji-yu-bu-er-biao-da-shi-de-guang-gao-suo-yin-she-ji.html
如果对本文有什么问题或疑问都可以在评论区留言,我看到后会尽量解答。
