30 分钟 Python 爬虫教程
30 分钟 Python 爬虫教程
长期以来,我一直计划利用 Python 配合 Selenium 编写一个网页爬虫,但迟迟未付诸实践。直到几天前,我决定动手实现它:从 Unsplash 网站抓取一些精美的图片。这听起来似乎是一项艰巨的任务,但实际上实现起来非常简单。

图片来源:Blake Connally 发布于 Unsplash.com
环境准备
在开始之前,请确保你的开发环境已准备好以下“原料”:
- Python(建议 3.6.3 或更高版本)
- Pycharm(社区版即可)
必要的 Python 库:
pip install requestspip install Pillowpip install selenium
- geckodriver(详见下文说明)
- Mozilla Firefox(若未安装)
- 正常的网络连接
- 大约 30 分钟的时间(甚至更少)
实战步骤
所有环境安装完毕后,我们先简要说明上述工具的作用,然后开始编写代码。
1. 配置 WebDriver
我们的首要任务是利用 Selenium WebDriver 和 geckodriver 打开一个浏览器窗口。
- 在 Pycharm 中新建一个项目。
- 根据你的操作系统下载最新版的
geckodriver。 - 将其解压,并把
geckodriver可执行文件拖到项目文件夹中。
geckodriver 本质上是让 Selenium 能够控制 Firefox 浏览器的驱动工具,项目需要它来执行浏览器自动化操作。
2. 打开目标页面
接下来,我们需要从 Selenium 中导入 webdriver 模块,并连接到想要爬取的 URL 地址。代码如下:
from selenium import webdriver
# 我们想要浏览的 URL 链接
url = "https://unsplash.com"
# 使用 Selenium 的 webdriver 来打开这个页面
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)运行代码后,将会打开浏览器窗口并访问指定 URL。
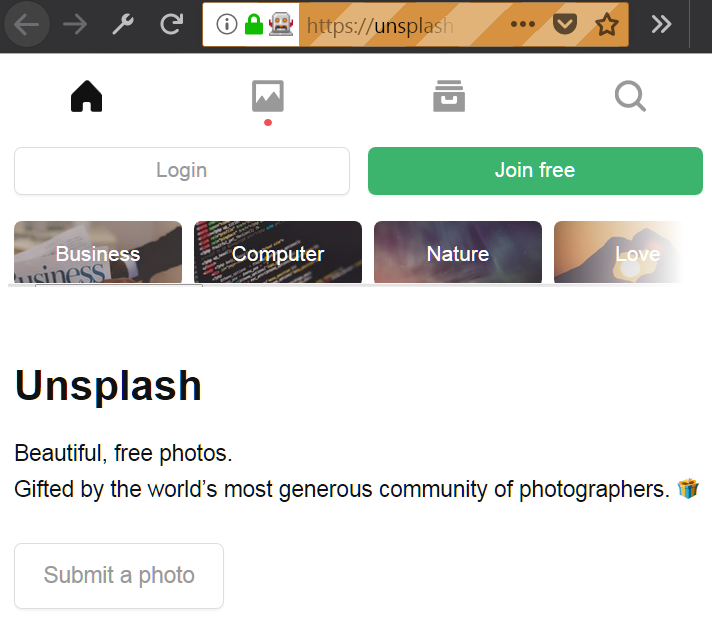
一个远程控制的 Firefox 窗口
这一步相当容易。如果一切正确,你应该能看到类似于上图所示的浏览器窗口。至此,你已经攻克了最难的部分。
3. 滚动页面与等待
接下来需要向下滚动页面,以便触发懒加载机制,让更多的图片加载出来。同时,我们需要等待几秒钟,以防网络连接较慢导致图片尚未完全加载。
由于 Unsplash 网站是使用 React 构建的,等待 5 秒钟通常已经足够。我们将使用 Python 的 time 模块进行等待,并使用 JavaScript 代码滚动网页——具体通过 [window.scrollTo()](https://developer.mozilla.org/en-US/docs/Web/API/Window/scrollTo) 函数实现。合并后的代码如下:
import time
from selenium import webdriver
url = "https://unsplash.com"
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
# 向下滚动页面并且等待 5 秒钟
driver.execute_script("window.scrollTo(0,1000);")
time.sleep(5)测试这段代码后,你应该会看到浏览器页面稍微向下滚动了一些。
4. 定位图片元素
下一步是找到我们要下载的图片。在探索了 React 生成的代码结构后,我发现可以使用一个 CSS 选择器来定位网页画廊中的图片。
虽然网页布局和代码未来可能会发生改变,但目前我们可以使用 #gridMulti img 选择器来获取屏幕上可见的所有 <img> 元素。
我们可以通过 [find_elements_by_css_selector()](http://selenium-python.readthedocs.io/api.html#selenium.webdriver.remote.webdriver.WebDriver.find_element_by_css_selector) 方法获取元素列表,但我们真正需要的是这些元素的 src 属性。我们可以遍历列表并逐一提取:
import time
from selenium import webdriver
url = "https://unsplash.com"
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
driver.execute_script("window.scrollTo(0,1000);")
time.sleep(5)
# 选择图片元素并打印出他们的 URL
image_elements = driver.find_elements_by_css_selector("#gridMulti img")
for image_element in image_elements:
image_url = image_element.get_attribute("src")
print(image_url)5. 下载并保存图片
为了真正获取找到的图片,我们将使用 requests 库发送 HTTP 请求,并结合 PIL(Pillow)库的 Image 模块处理图片。同时,利用 io 库中的 BytesIO 将图片数据写入文件夹 ./images/ 中(请确保在项目文件夹中预先创建该目录)。
流程如下:先向每张图片的 URL 发送 HTTP GET 请求,然后使用 Image 和 BytesIO 将返回的内容存储到本地。完整代码如下:
import requests
import time
from selenium import webdriver
from PIL import Image
from io import BytesIO
url = "https://unsplash.com"
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
driver.execute_script("window.scrollTo(0,1000);")
time.sleep(5)
image_elements = driver.find_elements_by_css_selector("#gridMulti img")
i = 0
for image_element in image_elements:
image_url = image_element.get_attribute("src")
# 发送一个 HTTP GET 请求,从响应内容中获得图片并将其存储
image_object = requests.get(image_url)
image = Image.open(BytesIO(image_object.content))
image.save("./images/image" + str(i) + "." + image.format, image.format)
i += 1这就是爬取一批图片所需的核心逻辑。显然,除非你只是想随便找些素材做设计原型,否则这个简易爬虫的用处可能有限。因此,我花了一些时间对其进行优化,增加了以下功能:
- 允许用户通过命令行参数指定搜索查询,以及指定向下滚动的次数,从而加载更多图片。
- 支持自定义 CSS 选择器。
- 基于搜索关键字自定义结果文件夹。
- 通过截断图片预览链接来获取全高清图片。
- 基于图片 URL 对文件进行命名。
- 爬取结束后自动关闭浏览器。
你可以(也应该)尝试自己实现这些功能。全功能版本的爬虫代码可以在 这里 下载。记得要先按照文章开头的说明,下载 geckodriver 并将其连接到你的项目中。
局限性与未来优化
整个项目是一个简单的“概念验证”(Proof of Concept),旨在弄清楚网页爬虫的基本实现原理。这意味着还有很多空间可以优化这个小工具:
- 版权致谢:没有致谢图片的原始上传者是不太合适的做法。Selenium 有能力获取这些信息,建议为每张图片标注作者名字。
- 驱动管理:
geckodriver不应该仅放在项目文件夹中,最好安装在全局环境下,并添加到系统的PATH环境变量中。 - 搜索扩展:搜索功能可以轻松扩展到支持多个查询关键字,从而简化下载多种类型图片的过程。
- 浏览器选择:默认浏览器可以用 Chrome 替代 Firefox,甚至可以使用 PhantomJS 替代,这对于此类无头浏览项目来说通常是更好的选择。
学习愉快!
说明:本文教程基于较早版本的 Selenium 库编写。请注意,Selenium 4.0 及以上版本中,find_elements_by_css_selector等方法已废弃,需改用find_elements(By.CSS_SELECTOR, ...)语法;同时executable_path参数也建议通过Service对象配置。此外,目标网站(Unsplash)的 DOM 结构可能随时间更新,文中提到的 CSS 选择器#gridMulti img可能需要根据实际情况调整。
版权声明:本文为原创文章,版权归 戴老师的博客 所有,转载请联系博主获得授权。
本文地址:https://1diff.fun/archives/30-fen-zhong-python-pa-chong-jiao-cheng.html
如果对本文有什么问题或疑问都可以在评论区留言,我看到后会尽量解答。
